SQLAlchemy 是 Python 生态中最流行的 ORM 类库,alembic 用来做 OMR 模型与数据库的迁移与映射,Flask-SQLAlchemy 是 Flask 的扩展,可为应用程序添加对 SQLAlchemy 的支持,简化 SQLAlchemy 与 Flask 的使用。
alembic_2">一.SQLAlchemy 和 alembic
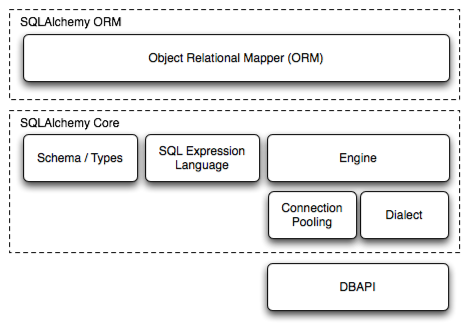
1.SQLAlchemy 介绍
SQLAlchemy 分成三部分:
- ORM:用类来表示数据库 schema 部分
- SQLAlchemy Core:一些基础操作,比如update、insert等,也可直接使用这部分来进行操作,但是写起来没有 ORM 那么简洁
- DBAPI:数据库驱动
安装 alembic 和 sqlalchemy 库:
pip install alembic
pip install sqlalchemy
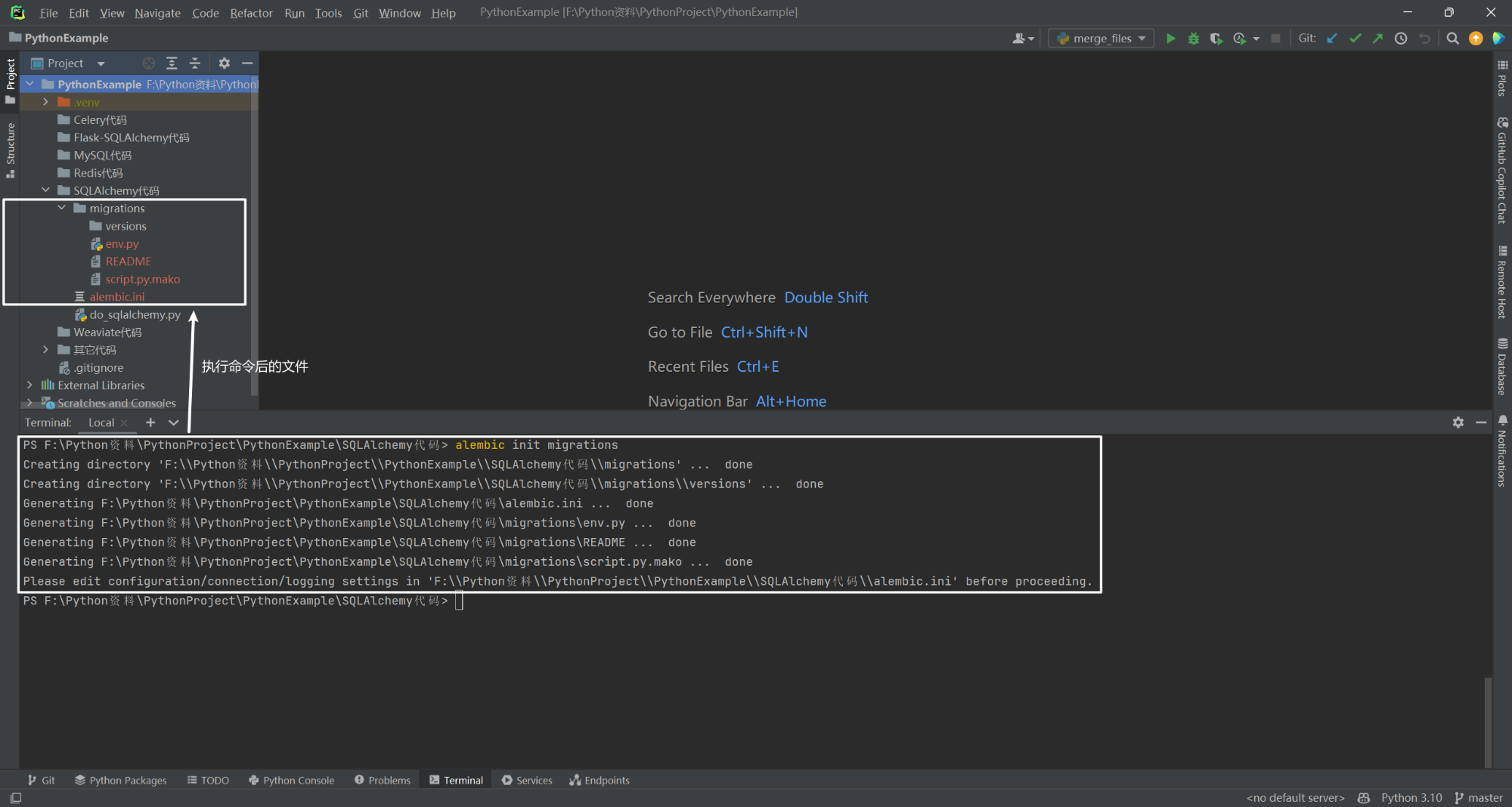
2.初始化 migrations 仓库
在项目目录中,执行命令 alembic init migrations,创建一个名叫 migrations 的仓库。
3.创建模型类
创建一个 models.py 模块,然后在里面定义模型类:
python">from sqlalchemy import Column,Integer,String,create_engine,Text
from sqlalchemy.orm import sessionmaker
from sqlalchemy.ext.declarative import declarative_base
Base = declarative_base()
class User(Base):
__tablename__ = 'user'
id = Column(Integer,primary_key=True)
username = Column(String(20),nullable=False)
password = Column(String(100),nullable=False)
class Article(Base):
__tablename__ = 'article'
id = Column(Integer,primary_key=True)
title = Column(String(100),nullable=False)
content = Column(Text, nullable=False)
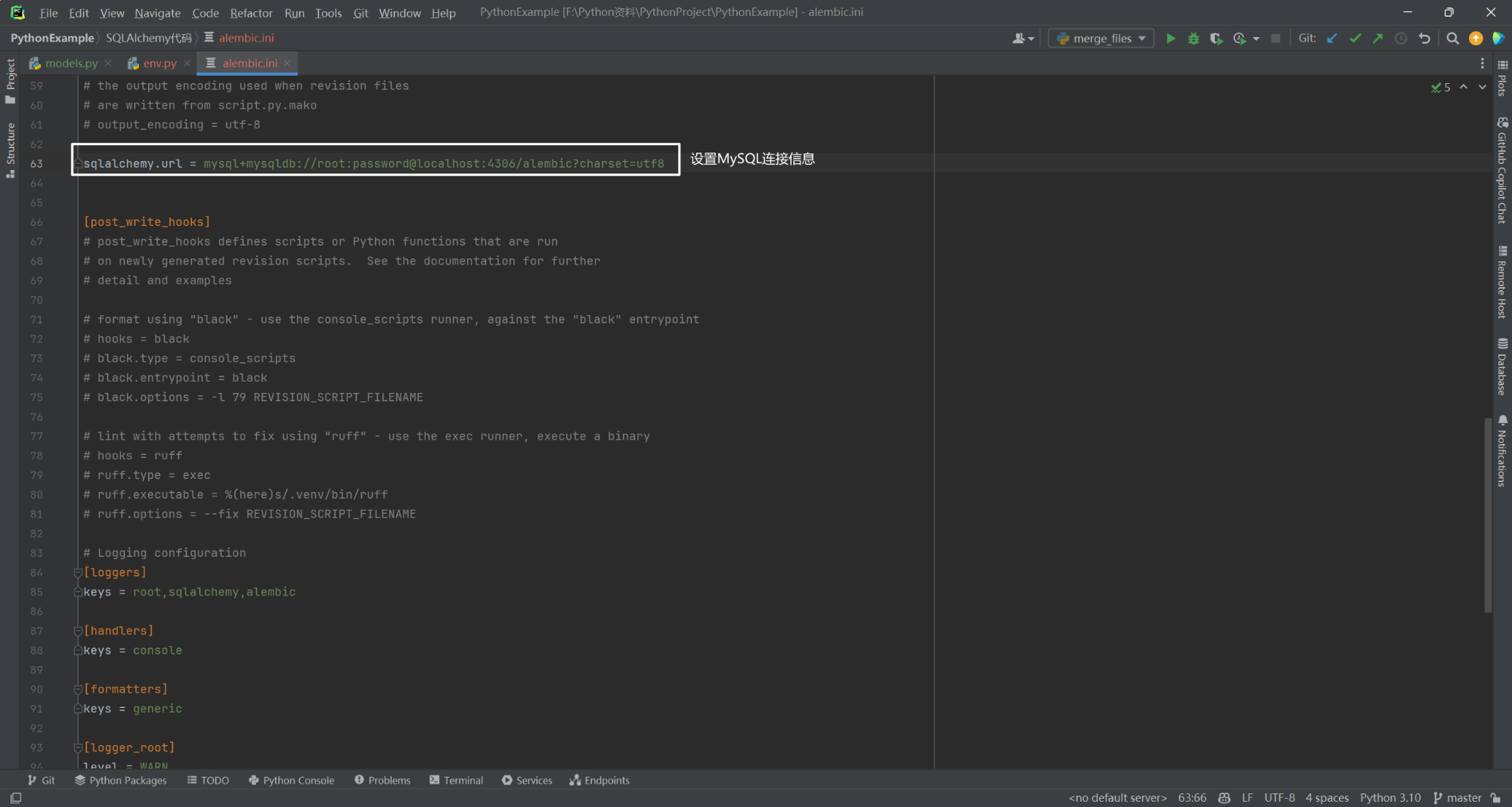
4.设置数据库连接
sqlalchemy.url = mysql+mysqldb://root:password@localhost:4306/alembic?charset=utf8
5.设置 target_metadata
为了使用模型类更新数据库,需要在 env.py 文件中设置 target_metadata,默认为 target_metadata=None。使用 sys 模块把当前项目的路径导入到 path 中:
python">import os
import sys
sys.path.append(os.path.dirname(os.path.abspath(__file__)) + "/../")
from models import Base
... #省略代码
target_metadata = Base.metadata # 设置创建模型的元类
... #省略代码

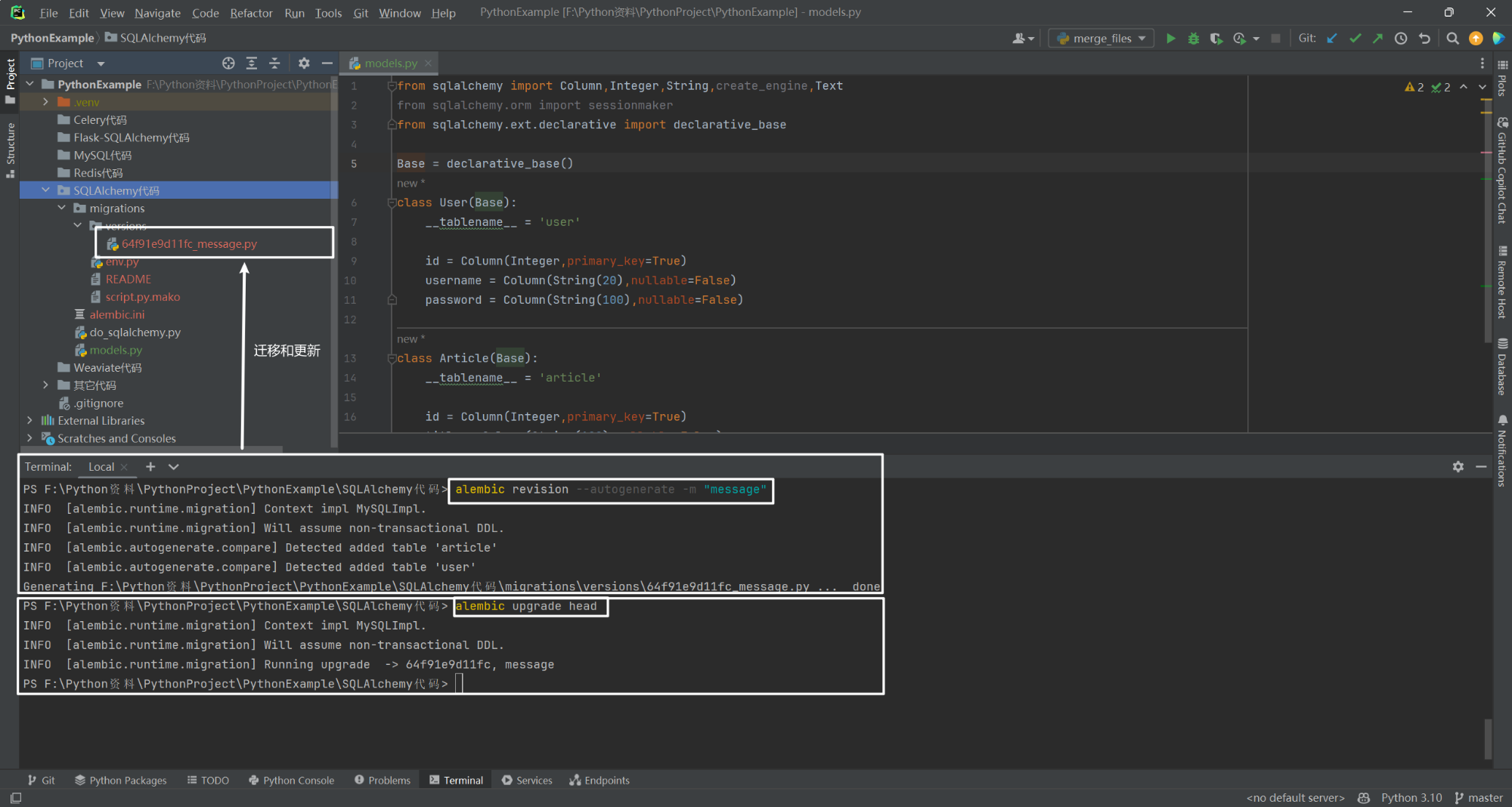
6.生成迁移文件
alembic revision --autogenerate -m "message"
7.更新数据库
alembic upgrade head
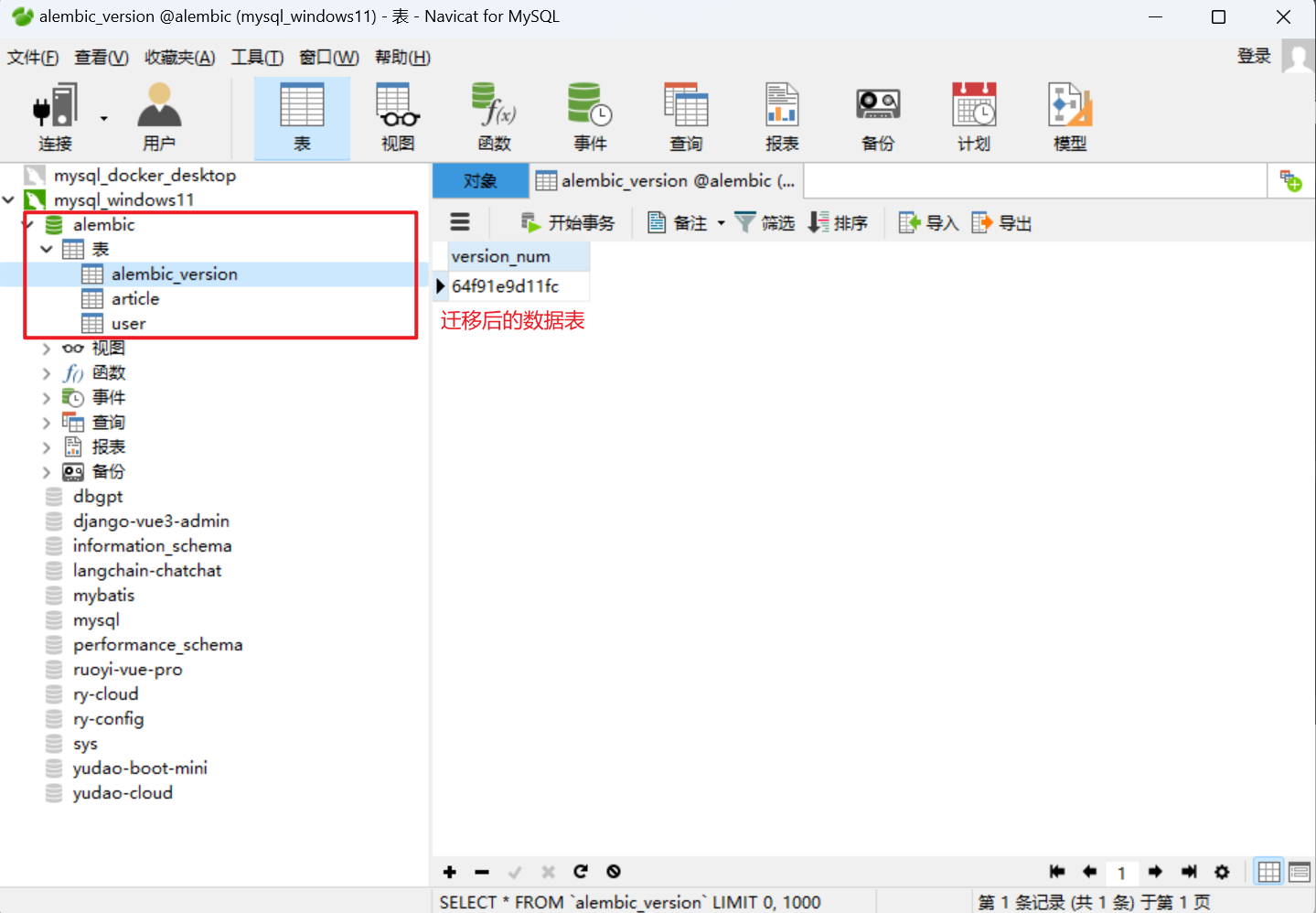
真正映射到数据库中的数据表文件:
如果要降级,那么使用 alembic downgrade head。
8.Alembic 常用命令
这些命令用于管理和应用数据库迁移,使数据库 schema 保持与模型同步。
| 命令 | 功能 |
|---|---|
init | 创建一个 Alembic 仓库 |
revision | 创建一个新的版本文件 |
–autogenerate | 自动将当前模型的修改生成迁移脚本 |
-m | 指定本次迁移的描述,方便回顾 |
upgrade | 将指定版本的迁移文件映射到数据库中,会执行版本文件中的 upgrade 函数。如果有多个迁移脚本没有被映射到数据库中,那么会执行多个迁移脚本 |
[head] | 代表最新的迁移脚本的版本号 |
downgrade | 执行指定版本的迁移文件中的 downgrade 函数 |
heads | 展示 head 指向的脚本文件版本号 |
history | 列出所有的迁移版本及其信息 |
current | 展示当前数据库中的版本号 |
在第一次执行 upgrade 的时候,就会在数据库中创建一个名叫 alembic_version 表,这个表只会有一条数据,记录当前数据库映射的是哪个版本的迁移文件。
二.Flask-Migrate
1.Flask-Migrate 介绍和安装
Flask-Migrate 是一个使用 Alembic 处理 Flask 应用程序的 SQLAlchemy 数据库迁移的扩展。
使用 pip 命令安装 Flask-Migrate:
pip install Flask-Migrate
2.Flask-Migrate 数据库迁移示例
这是一个通过 Flask-Migrate 处理数据库迁移的示例应用程序:
python">from flask import Flask
from flask_sqlalchemy import SQLAlchemy
from flask_migrate import Migrate
app = Flask(__name__)
# app.config['SQLALCHEMY_DATABASE_URI'] = 'sqlite:///app.db'
app.config['SQLALCHEMY_DATABASE_URI'] = mysql+mysqldb://root:password@localhost:4306/alembic?charset=utf8
db = SQLAlchemy(app)
migrate = Migrate(app, db)
class User(db.Model):
id = db.Column(db.Integer, primary_key=True)
name = db.Column(db.String(128))
通过上述应用程序,可使用以下命令创建迁移存储库:
flask db init

一种简单的解决方案:修改 User.py 为 app.py。如下所示:
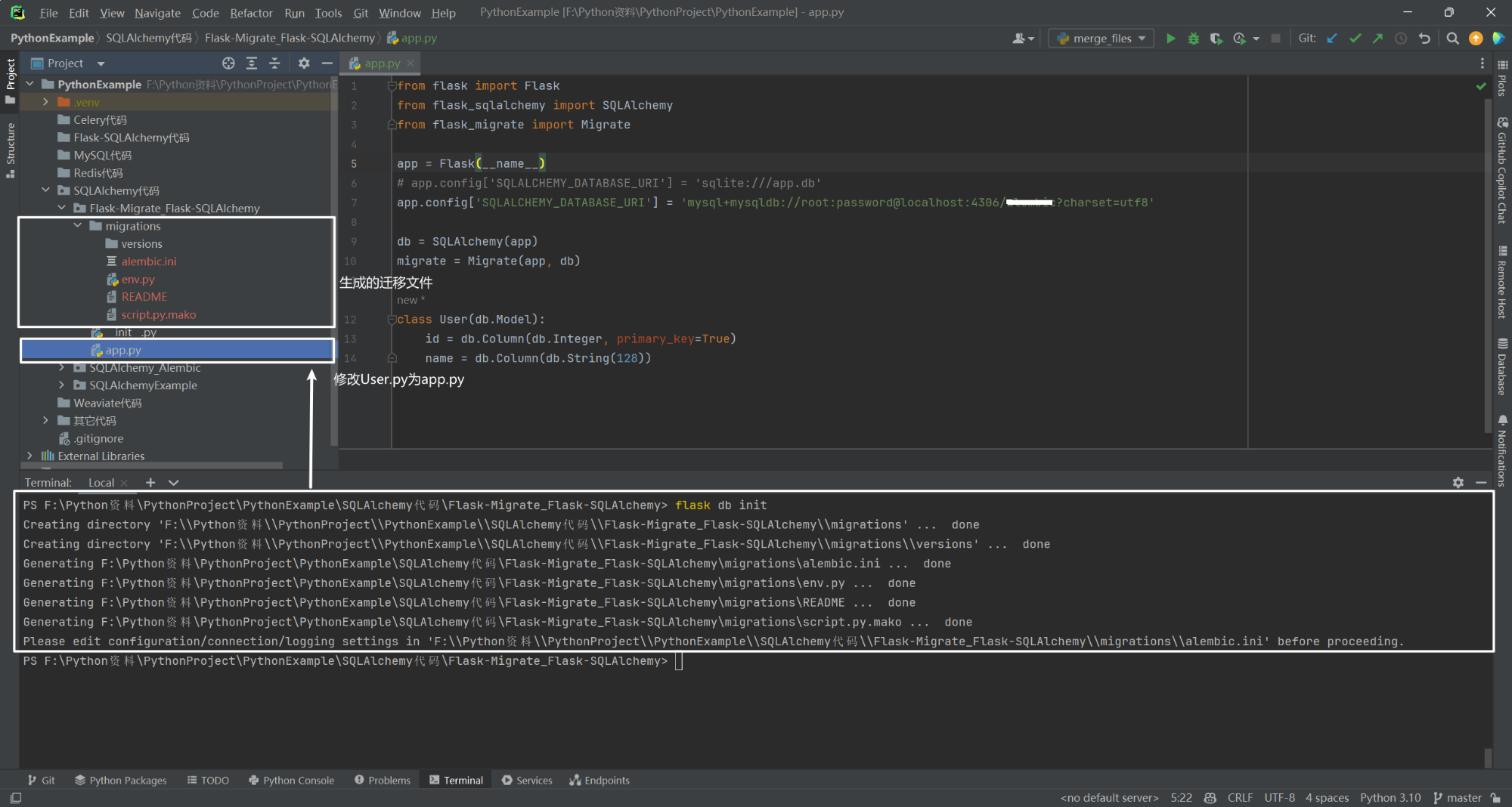
这会将迁移文件夹添加到应用程序中。该文件夹的内容需要与其它源文件一起添加到版本控制中,然后可生成初始迁移:
flask db migrate -m "Initial migration."

然后可将迁移脚本描述的更改应用到数据库:
flask db upgrade
执行 flask db upgrade 命令后生成的数据表:
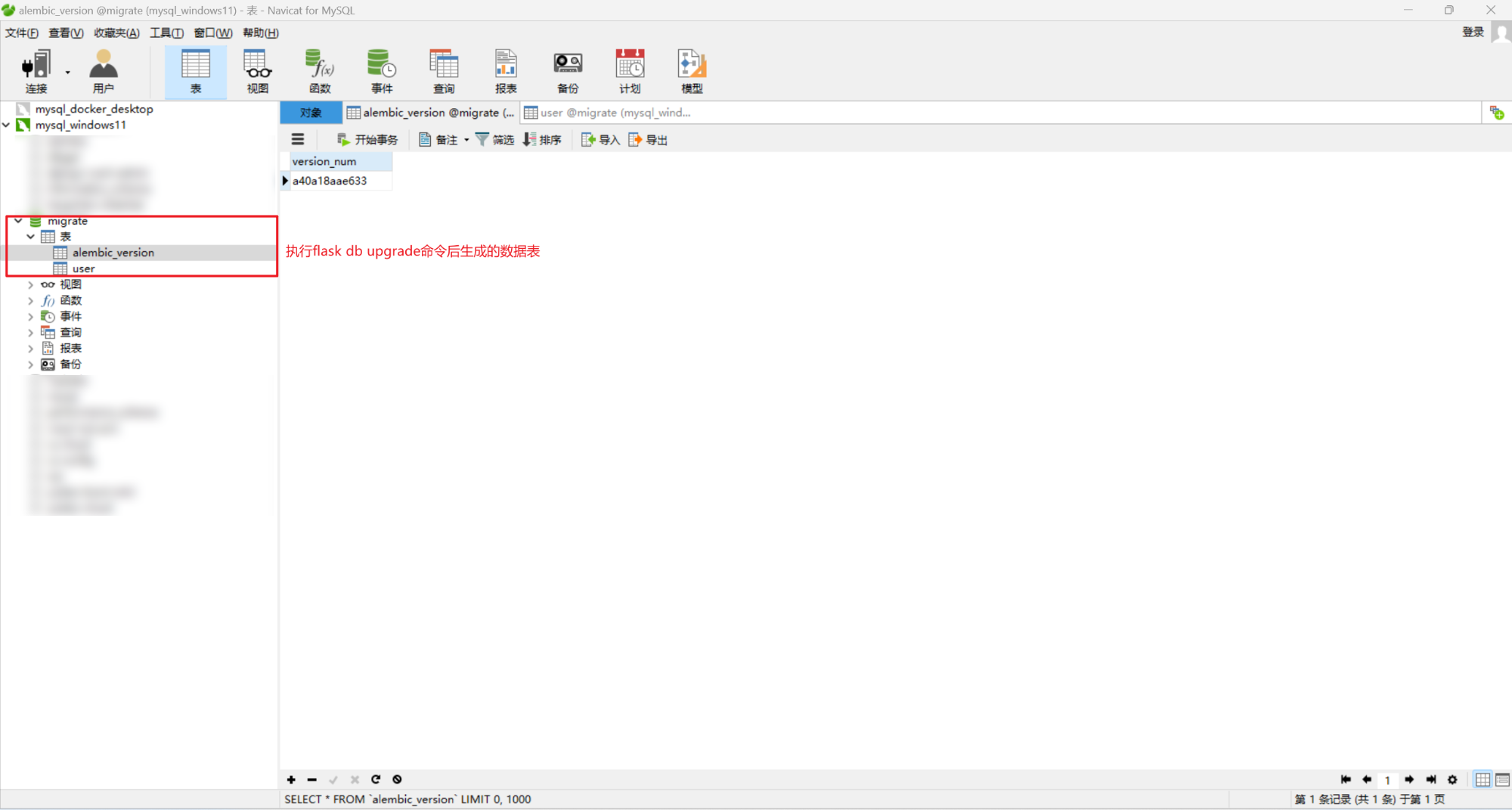
每次数据库模型更改时,请重复 migrate 和 upgrade 命令。
三.Flask-SQLAlchemy
1.Flask-SQLAlchemy 介绍和安装
Flask-SQLAlchemy 是 Flask 的扩展,可为应用程序添加对 SQLAlchemy 的支持。它旨在通过提供有用的默认值和额外的帮助程序来简化 SQLAlchemy 与 Flask 的使用,从而更轻松地完成常见任务。
pip install -U Flask-SQLAlchemy
2.实现 User 增删改查
python">from flask import Flask, request
from flask_sqlalchemy import SQLAlchemy
from flask_migrate import Migrate
from flask import jsonify
app = Flask(__name__) # 创建一个Flask实例
# app.config['SQLALCHEMY_DATABASE_URI'] = 'sqlite:///app.db'
app.config['SQLALCHEMY_DATABASE_URI'] = 'mysql+mysqldb://root:password@localhost:4306/migrate?charset=utf8'
db = SQLAlchemy(app) # 创建一个SQLAlchemy实例
migrate = Migrate(app, db) # 创建一个Migrate实例
class User(db.Model): # 创建一个User类,继承自db.Model
id = db.Column(db.Integer, primary_key=True) # 创建一个id列,主键
name = db.Column(db.String(128)) # 创建一个name列,字符串类型
# 创建用户
@app.route('/users', methods=['POST'])
def create_user():
data = request.get_json()
new_user = User(name=data['name'])
db.session.add(new_user)
db.session.commit()
return jsonify({'message': 'User created successfully'}), 201
# 获取所有用户
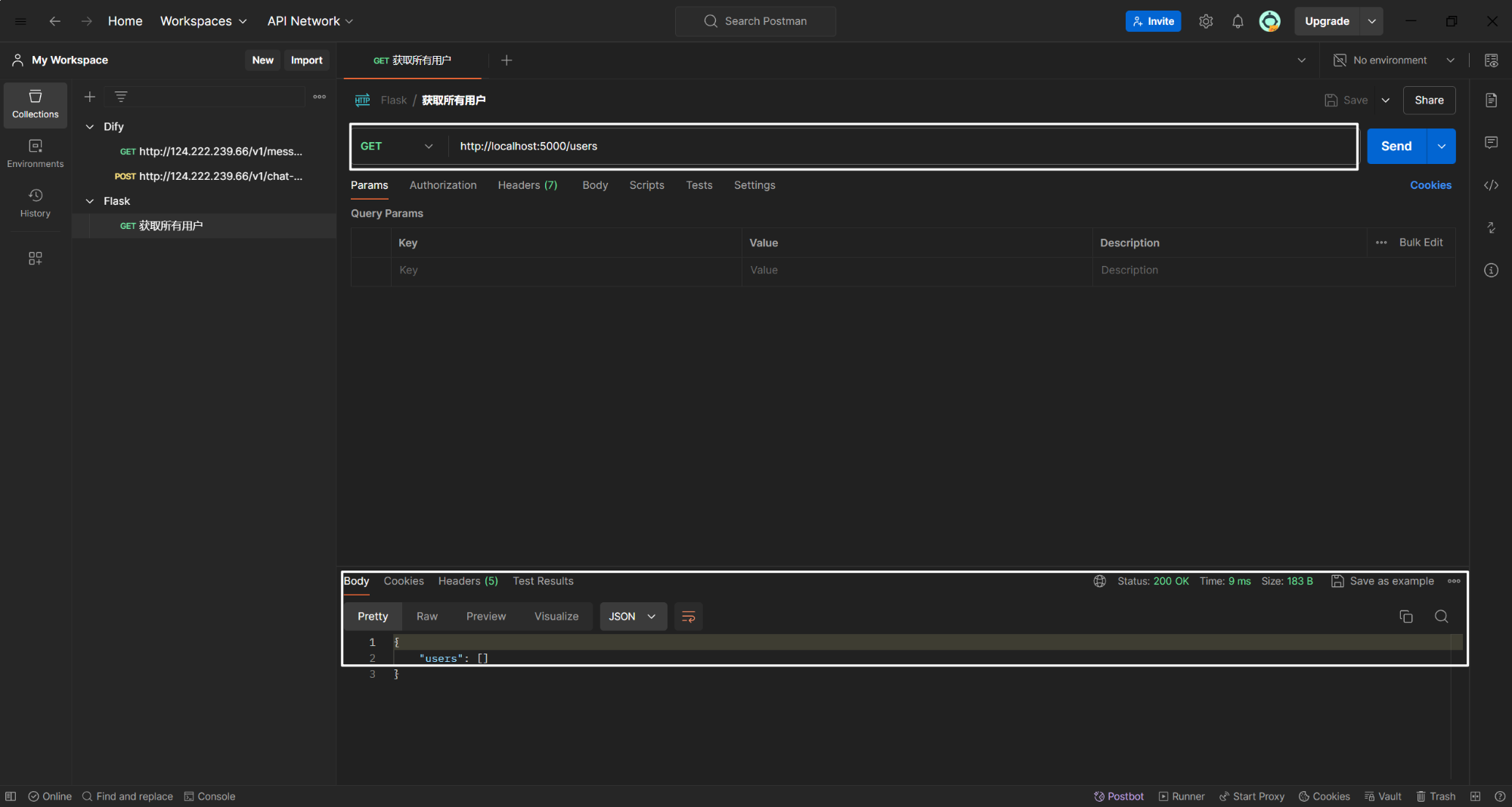
@app.route('/users', methods=['GET'])
def get_users():
users = User.query.all()
output = []
for user in users:
user_data = {'id': user.id, 'name': user.name}
output.append(user_data)
return jsonify({'users': output})
# 获取单个用户
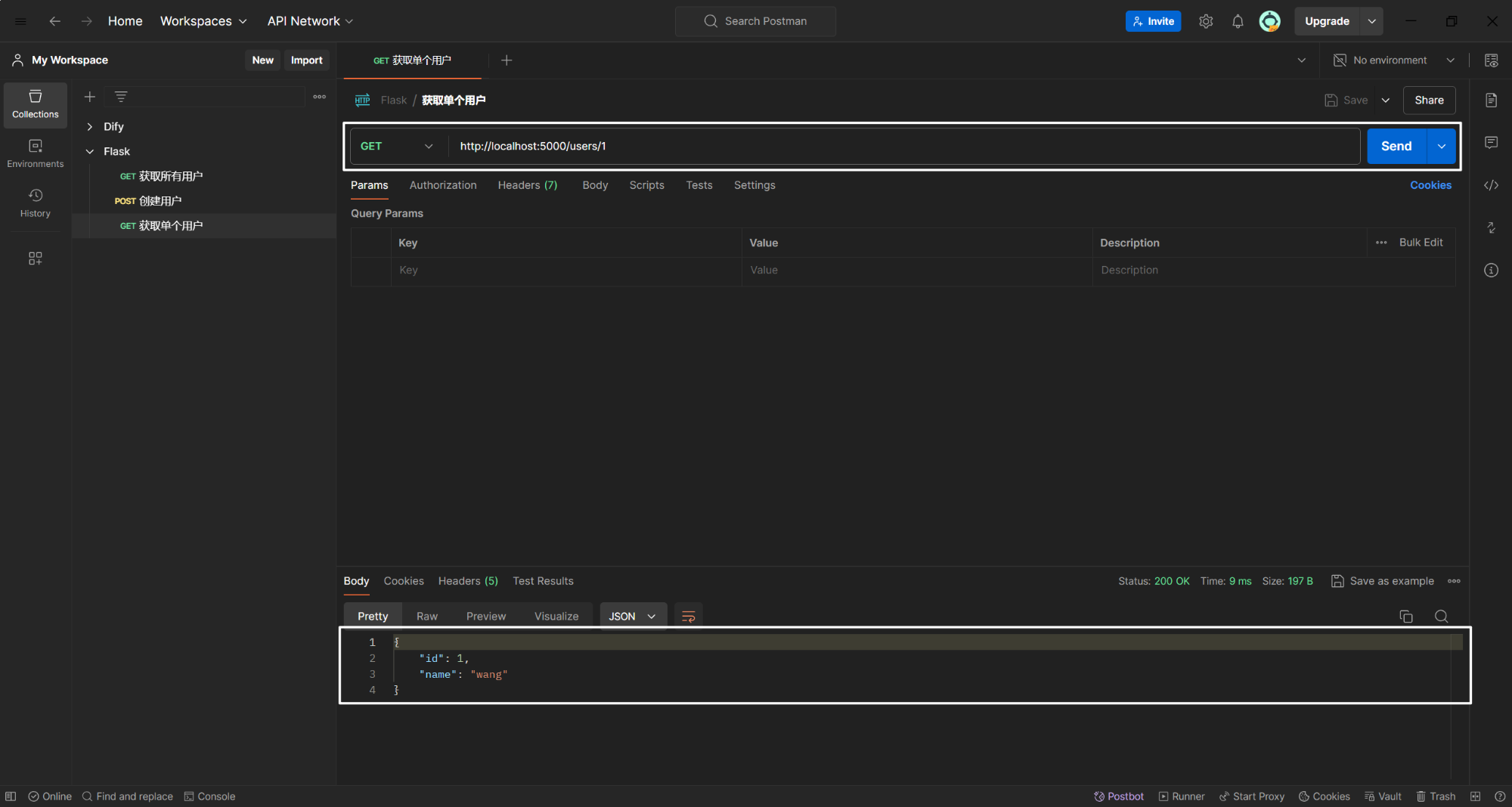
@app.route('/users/<id>', methods=['GET'])
def get_user(id):
user = User.query.get_or_404(id)
return jsonify({'id': user.id, 'name': user.name})
# 更新用户
@app.route('/users/<id>', methods=['PUT'])
def update_user(id):
data = request.get_json()
user = User.query.get_or_404(id)
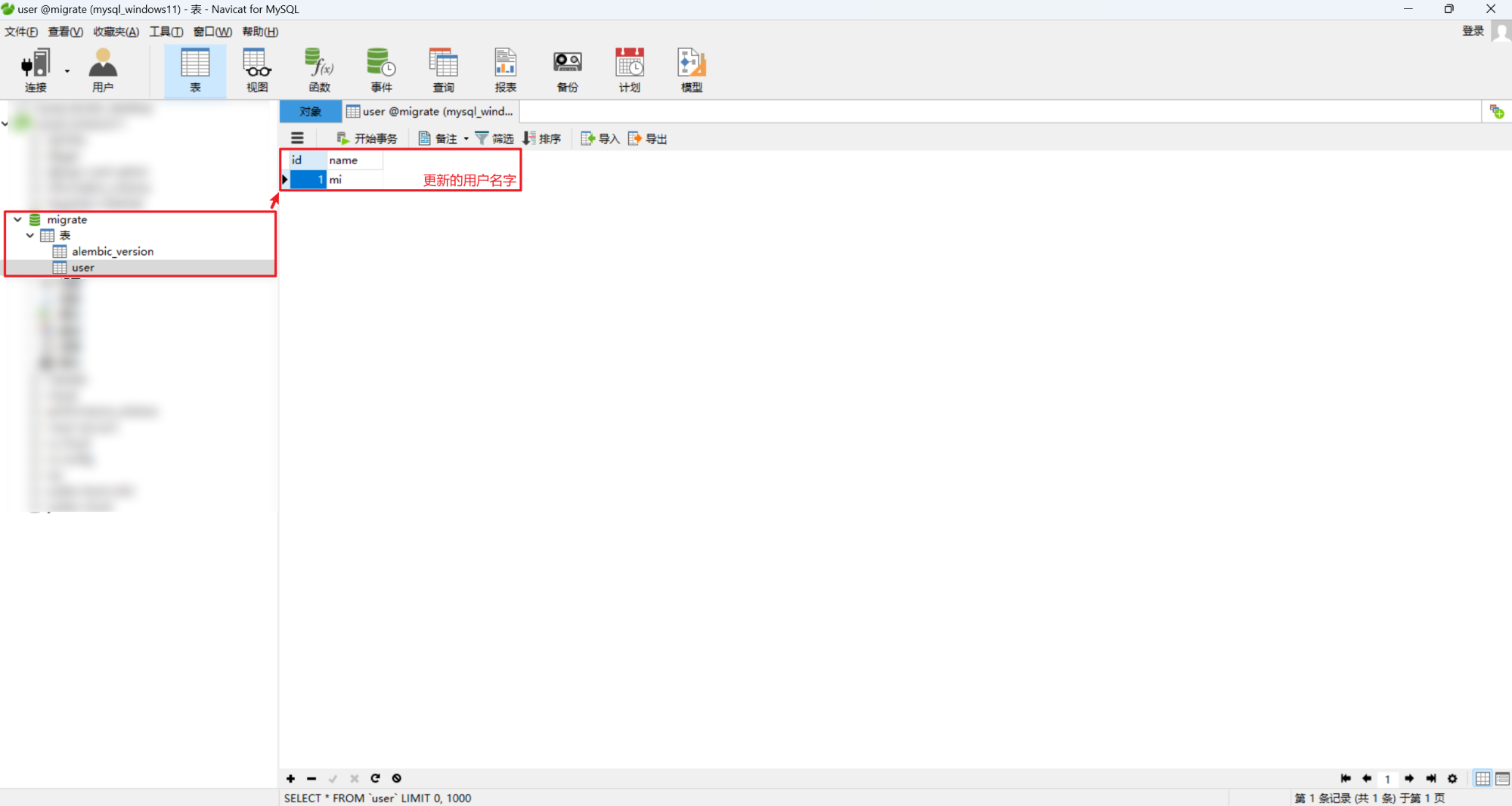
user.name = data['name']
db.session.commit()
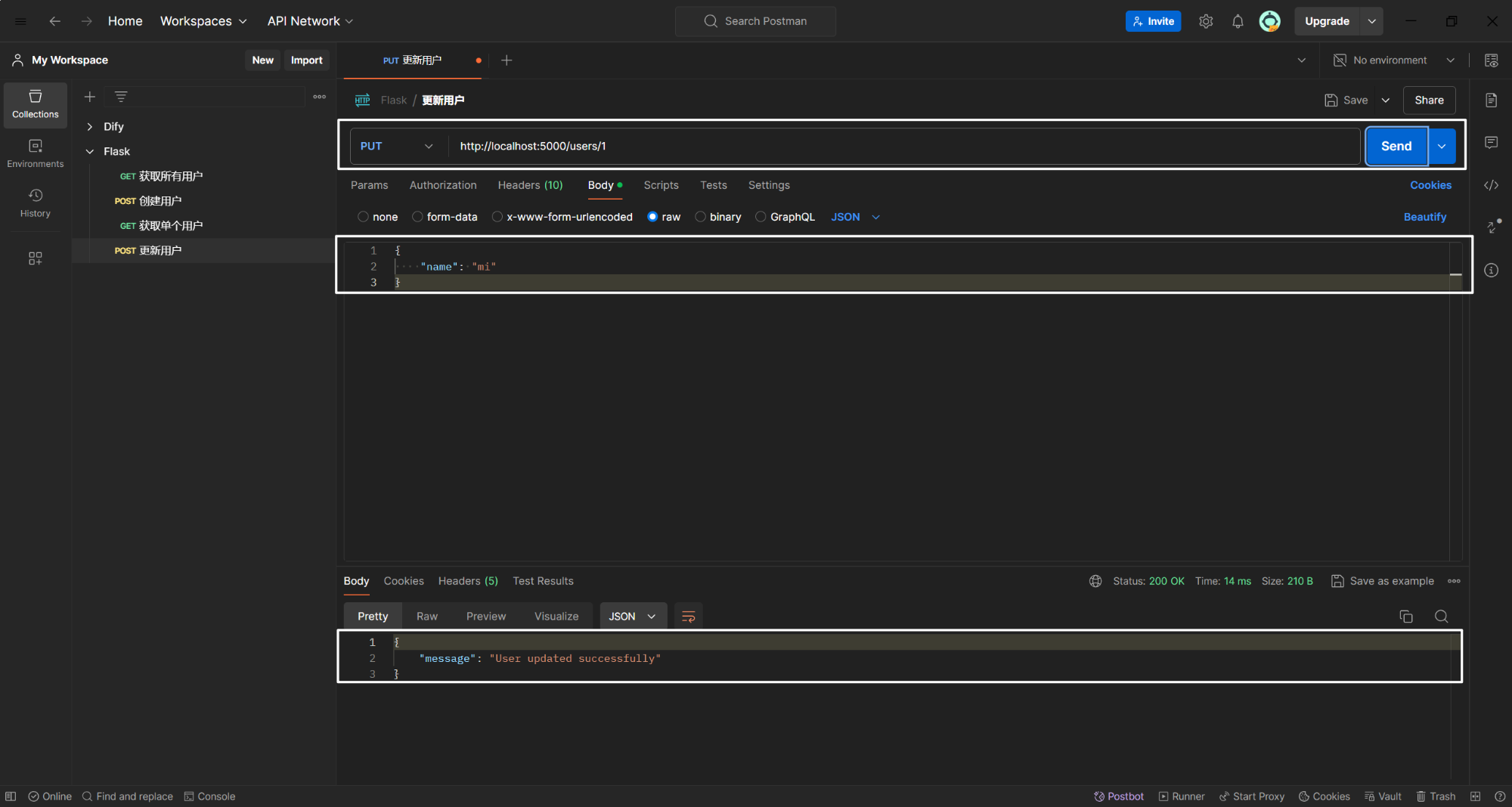
return jsonify({'message': 'User updated successfully'})
# 删除用户
@app.route('/users/<id>', methods=['DELETE'])
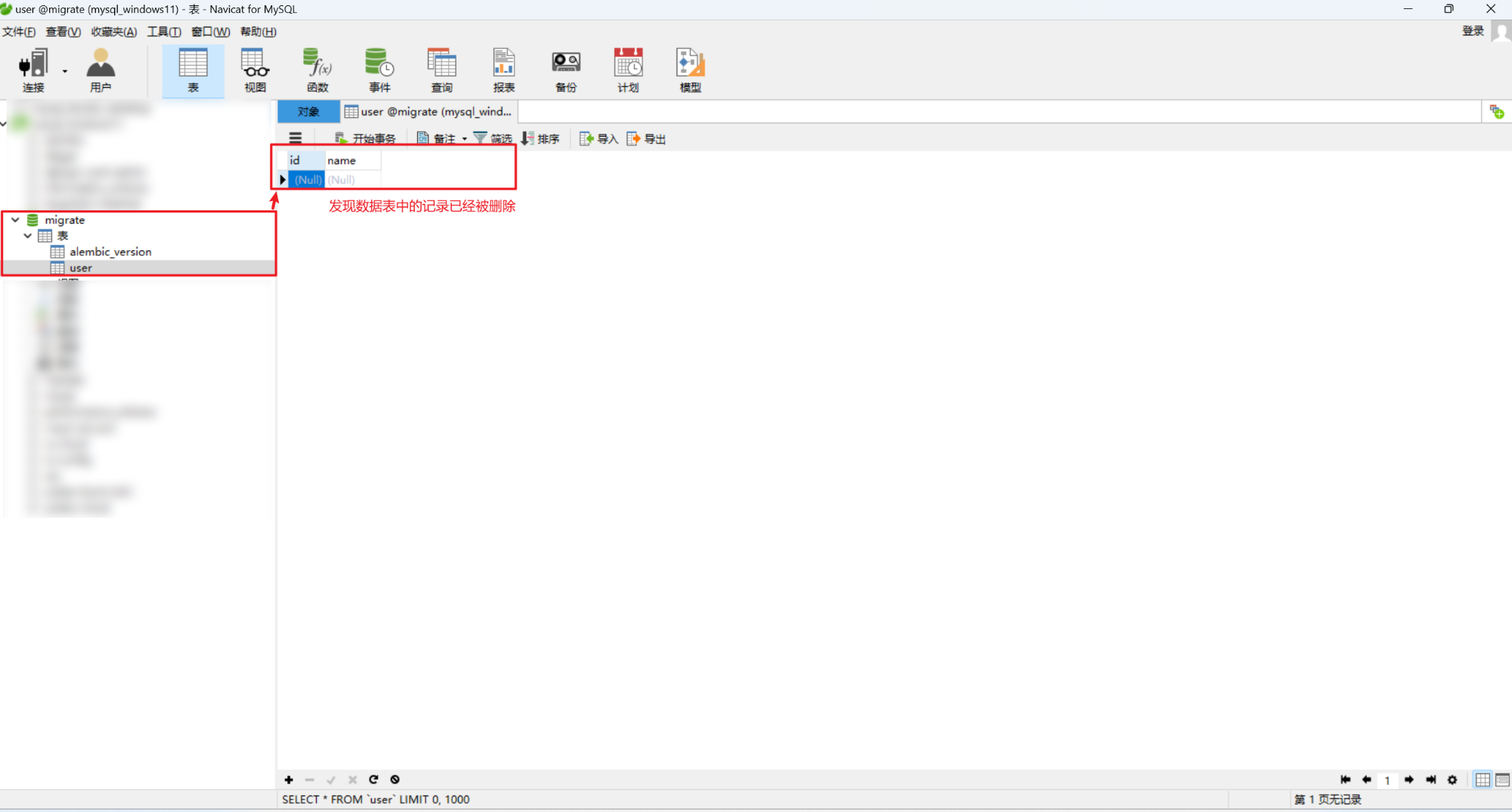
def delete_user(id):
user = User.query.get_or_404(id)
db.session.delete(user)
db.session.commit()
return jsonify({'message': 'User deleted successfully'})
if __name__ == '__main__':
app.run(debug=True) # 运行Flask应用

(1)获取所有用户
(2)创建用户
在 Headers 中设置 Content-Type: application/json。如下所示:


(3)获取单个用户
(4)更新用户
在 Headers 中设置 Content-Type: application/json。如下所示:
(5)删除用户

参考文献
[1] alembic:https://alembic.sqlalchemy.org/en/latest/index.html
[2] SQLAlchemy:https://docs.sqlalchemy.org/en/20/
[3] Flask-SQLAlchemy:https://flask-sqlalchemy.palletsprojects.com/en/3.1.x/
[4] alembic 教程:https://hellowac.github.io/technology/python/alembic/
[5] SQLAlchemy 2.0 教程:https://yifei.me/note/2652
[6] Flask-Migrate:https://flask-migrate.readthedocs.io/en/latest/
[7] Flask-Migrate GitHub:https://github.com/miguelgrinberg/flask-migrate
[8] Flask-SQLAlchemy 快速入门:http://www.pythondoc.com/flask-sqlalchemy/quickstart.html